Zdeněk Kasner
NLP researcher
Research
NLP researcher
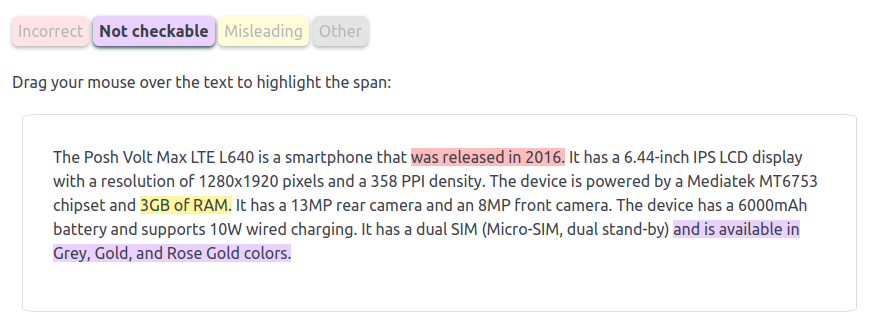
My research revolves around improving data-to-text generation systems.
The projects I have worked on include:
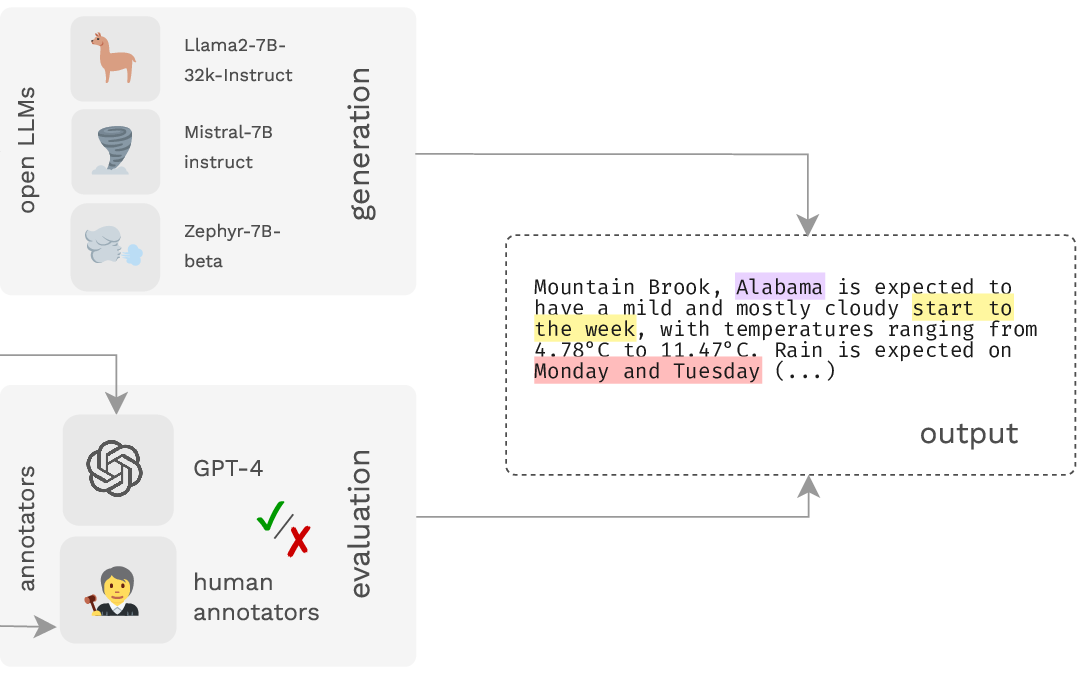
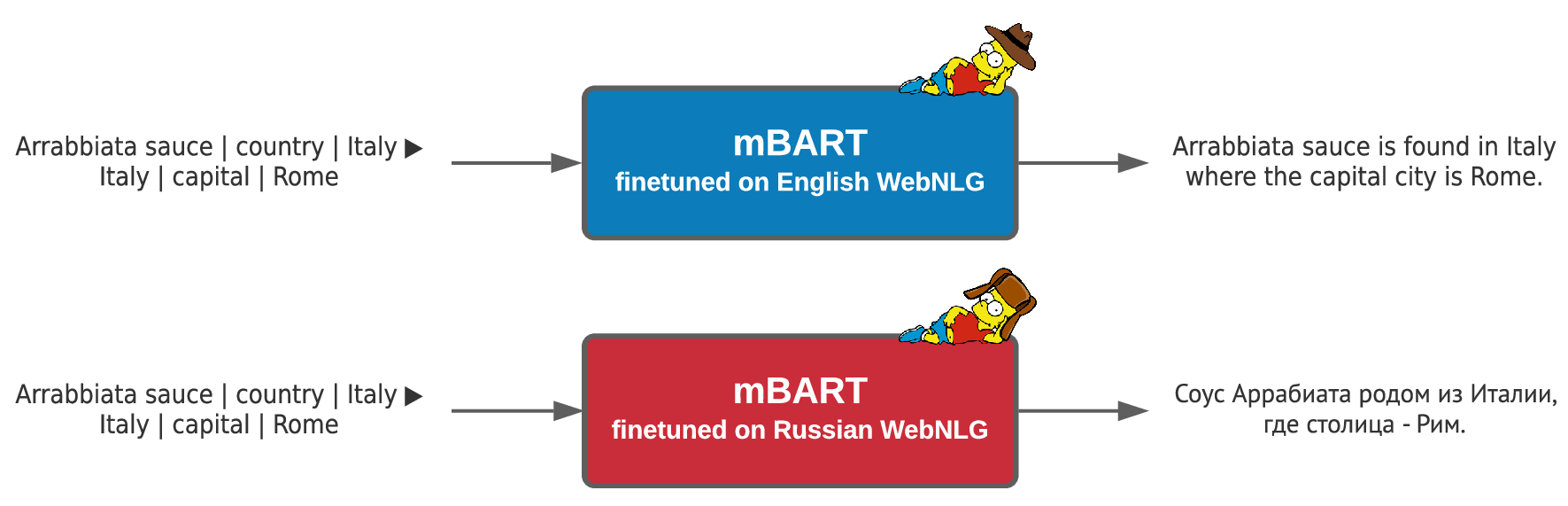
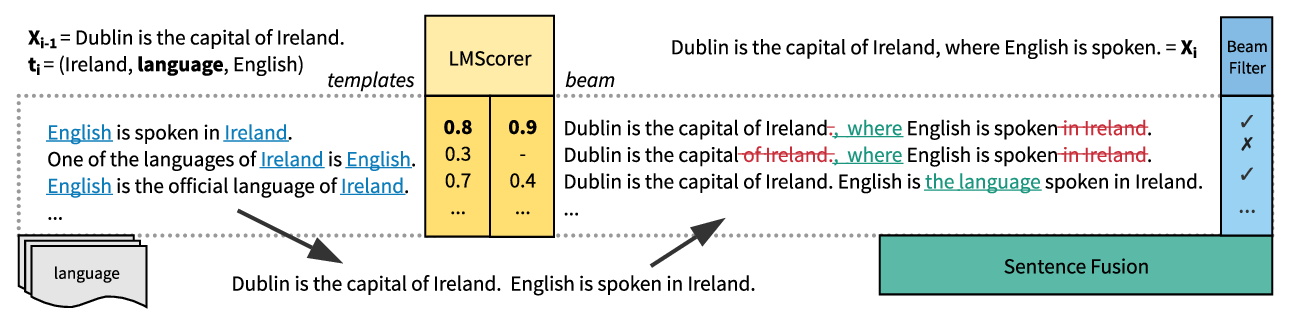
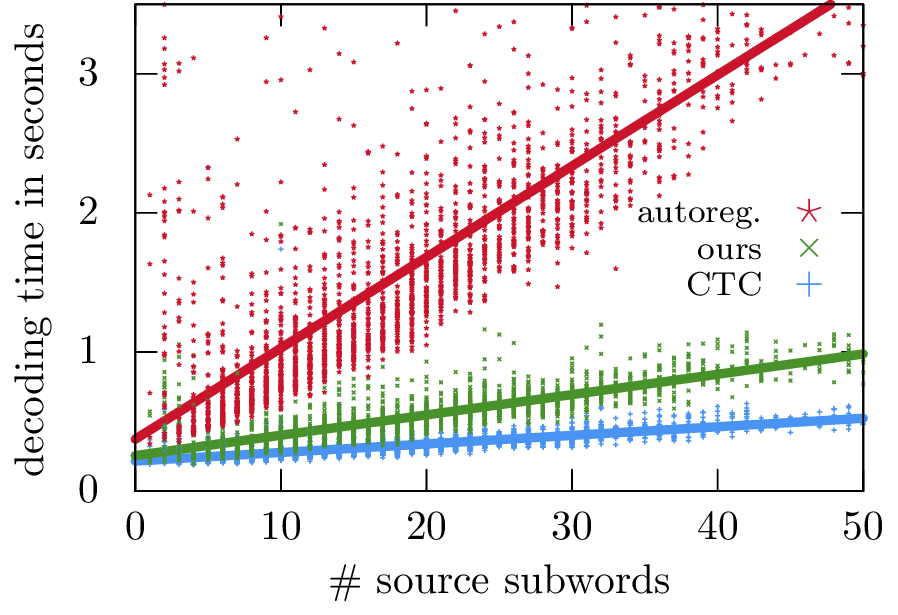
I focus on developing efficient representations of structured data, so that the data can be used as an input to pretrained language models for generating automated reports.
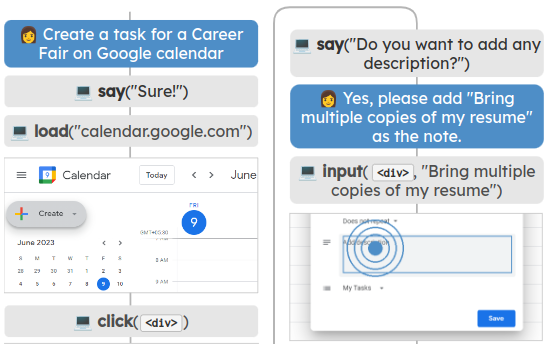
During my internship at Mila, I was working on applying LLMs for autonomous web navigation.
In the future, I would also like to delve deeper into model interpretability: how is the information inside the language models represented, how do language models reason, and how this all relates to human cognition.