Zdeněk Kasner
NLP researcher
Research
NLP researcher
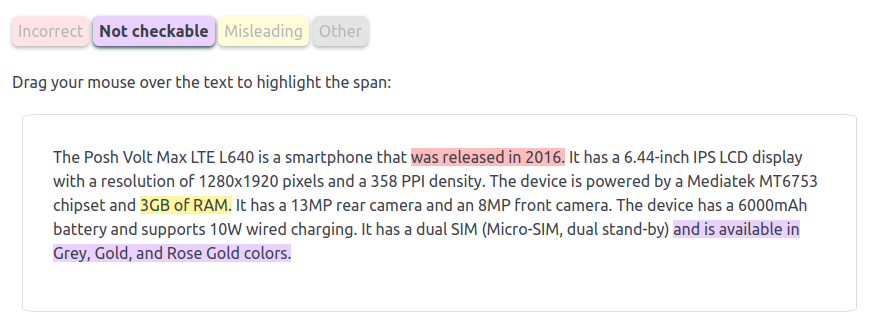
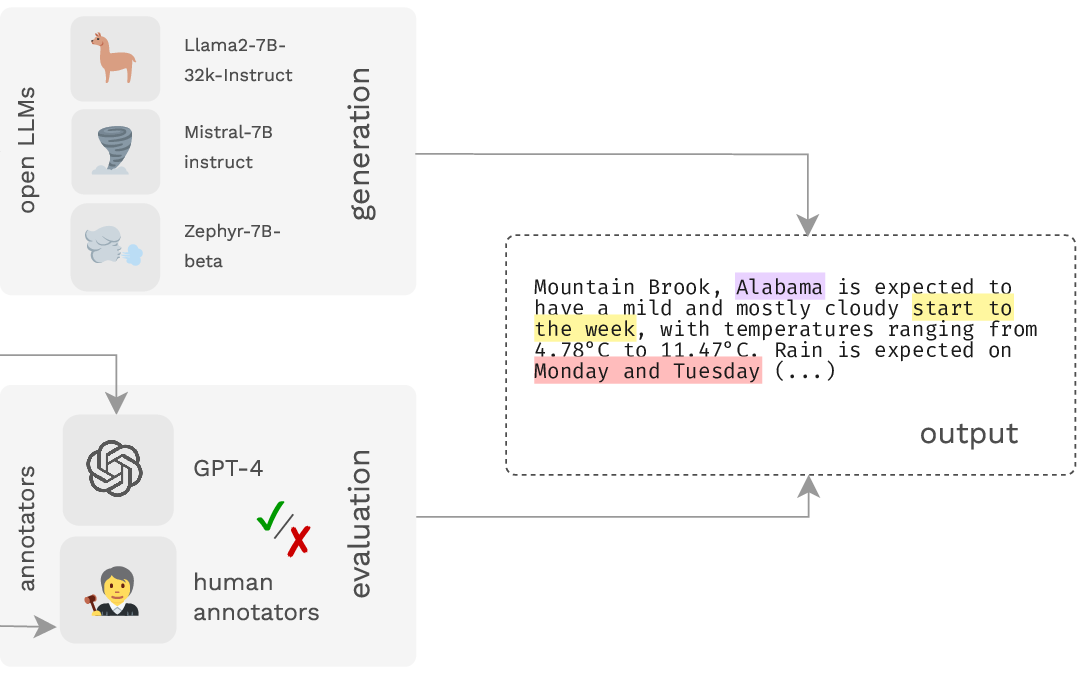
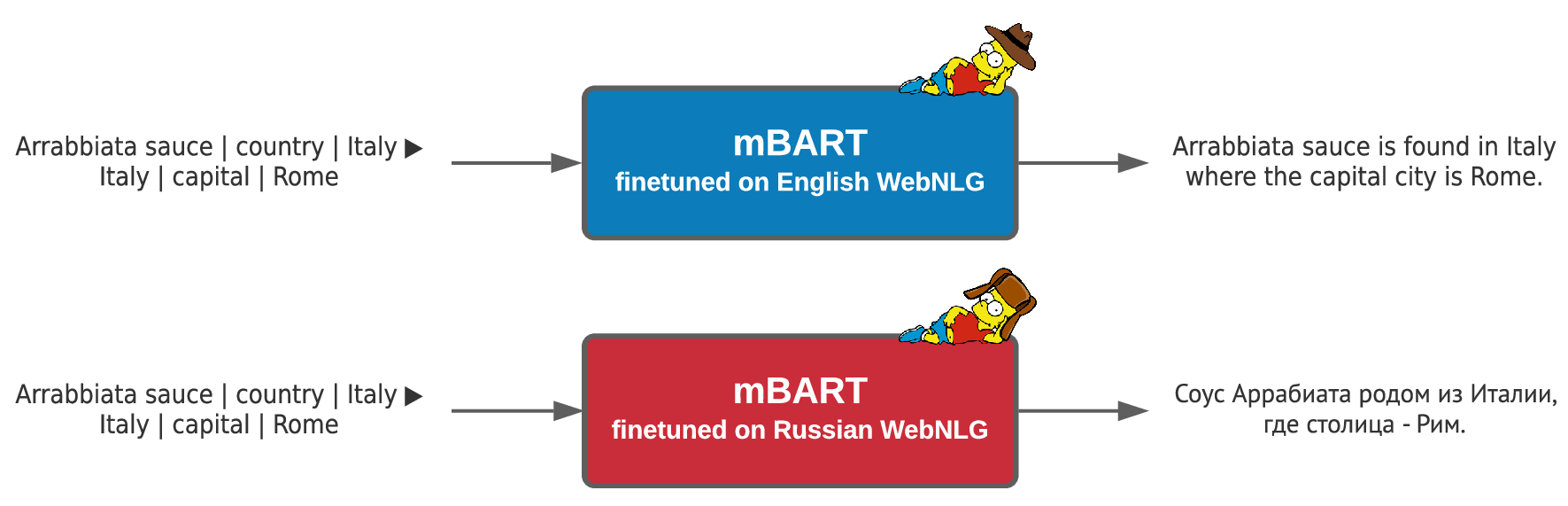
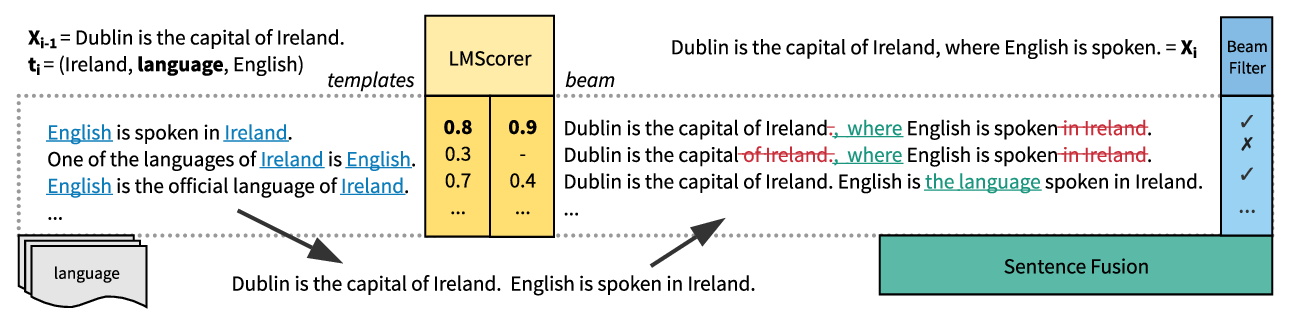
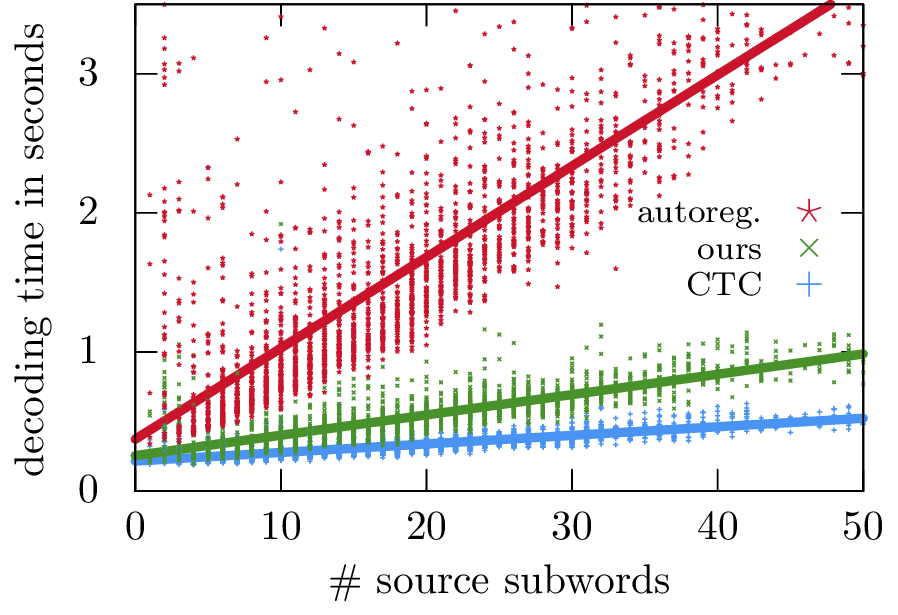
In my research, I focus on making sure that large language models (LLMs) generate accurate text.
The projects I have worked on include:
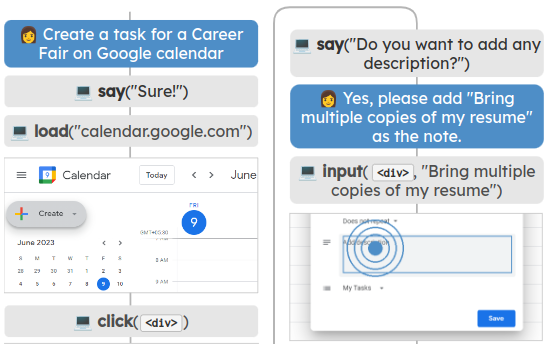
During my internship at Mila–Quebec AI institute, I was also working on applying LLMs for autonomous web navigation [11].
If I only had enough time, I would dig into many more things! For example, I am interested in how is the information inside the language models represented, how this all relates to human cognition, and how can we use AI tools to make our lives better.